


























What happens when you apply Charles Darwin’s concepts of specialization, adaption, and inheritance to information architecture? Keep reading to find out.
First things first – DITA stands for Darwin Information Typing Architecture. It’s an Extensible Markup Language (XML)-based open standard for developing, managing, structuring, and publishing content for print as well as for the web. Unlike a Word document (which produces a static piece of content), each piece of DITA content represents a unique XML file. By standardizing content, DITA makes reuse across multiple publications a snap. DITA is principally used in the computer software, information technology, telecoms, and medical device industries, but it’s consistently expanding into a variety of new industries.
Where does Charles Darwin enter the picture?
DITA is more than just a methodology – it’s a philosophy. Darwin’s theory of natural selection is based on the idea that species adopt traits from their parents. DITA incorporates the same notions of inheritance, specialization, and adaptation – just in a different field! Because all DITA topic types and elements exist in a “parent-child” relationship, inheritance and specialization are crucial.
Why use DITA?
A narrative-style approach to technical writing, where an author begins at page 1, is not a workable solution once updates, product functionality variations, and localization are factored in. Because DITA forces authors to focus on single topics rather than a logical progression of chapters, the hardest part of implementing DITA is the adjustment to this paradigm shift. This can initially be a tough change, but the eventual benefits outweigh the initial learning curve. Other benefits of switching to DITA include:
- DITA is organized into core topic types which allow you to reuse topics like building blocks to create any format you like.
- Targeting different users with personalized documentation is straightforward. A medical device manufacturer that sells cardiac pacemakers but needs to provide different technical documentation for physicians and patients has their life made easier because with DITA, topics that are overly technical can be removed from the patient documentation.
- Because DITA is based on XML, the content and format are separate. This means that arduous changes only need to be done once – your content will update automatically.
- DITA increases productivity by encouraging collaboration. Because of its topic-based approach, multiple writers can work on the same document simultaneously.
- Localization savings can also justify a move to DITA. Your business can quickly and easily identify new or changed topics for translation, meaning that you only need to translate content once.
- Content and format are handled separately, so hours of desktop publishing (DTP) work are no longer necessary.
A solution to every problem
Based on our unique understanding of how DITA works, we have developed a solution for this. The key to DITA content is the DITAMAP – a file that serves as the blueprint for a publication and lists the eventual order of the DITA files. We have created a tool which reads the DITAMAP file and organizes the DITA files into the correct order.
How it works
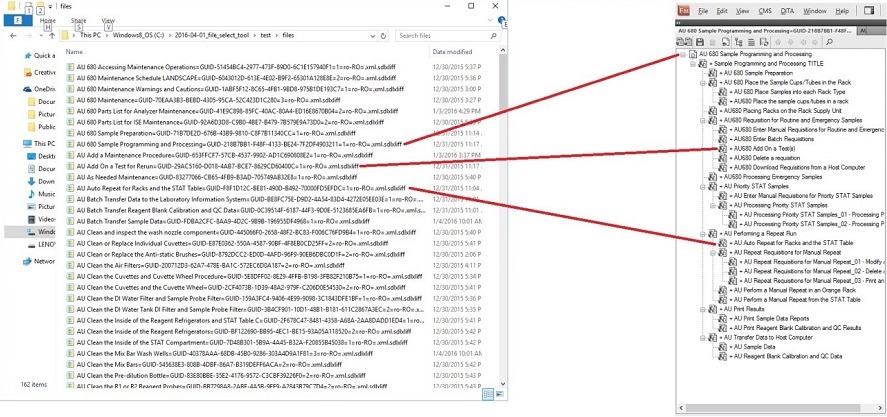
The screens below show how we can accommodate a client who asks for the review of only one chapter (in this case, it’s the Sample Programming and Processing chapter, which contains 32 files) of a document containing 162 files. The screen to the left shows the full list of translated files in alphabetical order, while the DITAMAP visualization through FrameMaker to the right shows us the order but also splits the chapter into several sections and sub-sections that mimic the eventual publication structure. We’ve highlighted how three of the DITA information chunks fall into the eventual structure:
The other common issue linguists can have with DITA is understanding how a file is eventually represented once published. In flowing text this is not typically a problem, but the DITA framework does allow the use of some sophisticated elements that can appear confusing to linguists. Examples of this are complex table and list layouts or elements that are part of the DITA user interface domain (a special set of DITA elements designed to document user interface tasks, concepts, and reference information.) An element contains one or more user interface control () elements, and when there is more than one element, the formatter shows connecting characters between the menu items to represent the menu cascade.
In the following example:

produces the following output:
Start > Programs > Accessories > Paint
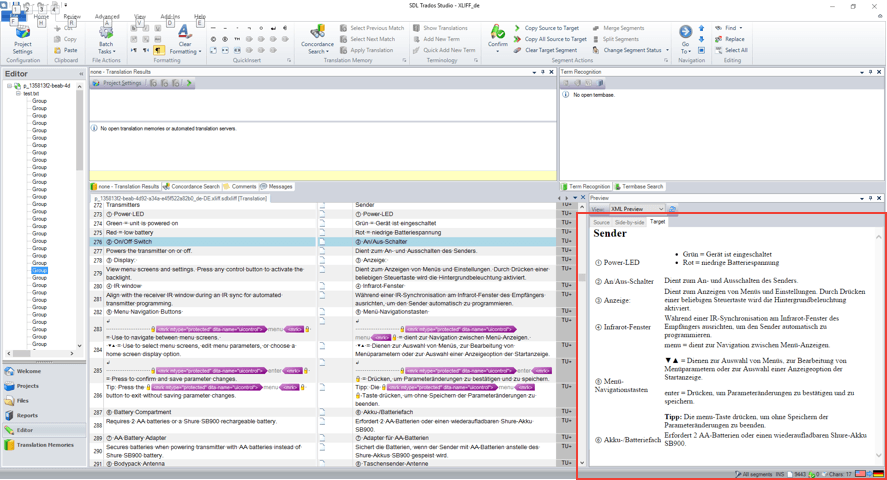
Once a document starts to use multiple elements and references, the chain of elements can become harder to understand. For that reason, we’ve created a plugin that uses the xslt transformation file supplied by a client in order to generate an XML preview of the DITA text directly in Trados Studio. You can see how this preview looks in the red box in the screenshot below. This way, even more complex layouts (such as the ones shown below) can be easily visualized by the linguist, making translation a much simpler task.
If your business is planning to move its authoring to a DITA environment, get in touch with our team for more information about how we can take the pain out of your localization process.
Argos Multilingual is now Across 7 certified by the market leader in translation software after completing both a rigorous online training session on the key new features of version 7 and a comprehensive system check. As we were previously Across certified, the new certification process focused on the primary benefits of the new version, which include […]

It may sound paradoxical, but following a few simple suggestions can produce more accurate translations while also helping you get the most out of your resources. Read on to see how it’s possible! The old adage that “you get what you pay for” suggests that we should forfeit any expectation of quality when we opt […]



