







#2 Customer Review: SME
Articles
・4 min read
Published on




DITA has been established as a method of reducing global publishing costs. That is not to say that there are no challenges when it comes to localization.
Because DITA content is designed to be built from small independent “topic chunks”, linguists are usually able to translate each chunk without the need for much additional context – legal information will be separate from warnings, which will be separate from the chunks which describe each piece of functionality. Because of this, a linguist can be supplied with a PDF of the final published output which will normally provide any missing context.
But what happens when you need to review one translated chapter from a large manual containing 20 or more chapters? While it would previously have been easy to identify the chapter requiring review, each chapter might now be made up from 35 files out of a total of more than 650 which make up the whole manual. This can be where your LSP fails because of a lack of understanding of the way in which DITA works.
The key to DITA content is the DITAMAP – a file which acts as the blueprint for a publication and lists the eventual order of DITA files. Because Argos understands how DITA works, we have developed a solution for this. We have created a tool which reads the DITAMAP file, and organizes the DITA files into the correct order.
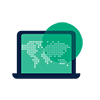
The screens below show how Argos is able to accommodate a client who asks for the review of only one chapter (in this case the Sample Programming and Processing chapter containing 32 files) of a document containing 162 files. The screen to the left shows the full list of translated files in a flat and alphabetical order, while, the DITAMAP visualization through FrameMaker to the right shows us not only the order, but also splits the chapter into a number of sections and sub-sections which mimic the eventual publication structure.
We have highlighted how three of the DITA information chunks fall into the eventual structure.
The other issue linguists can have with DITA is understanding how a file is eventually represented once published. In flowing text this is not normally a problem, but the DITA framework does allow the use of some sophisticated elements which can appear confusing to linguists.
Examples of this are complex table and list layouts or with the element. This element is part of the DITA user interface domain; a special set of DITA elements designed to document user interface tasks, concepts and reference information. A element contains one or more user interface control () elements. When there is more than one element, the formatter shows connecting characters between the menu items to represent the menu cascade.
In the following example;

produces this output:
Start > Programs > Accessories > Paint
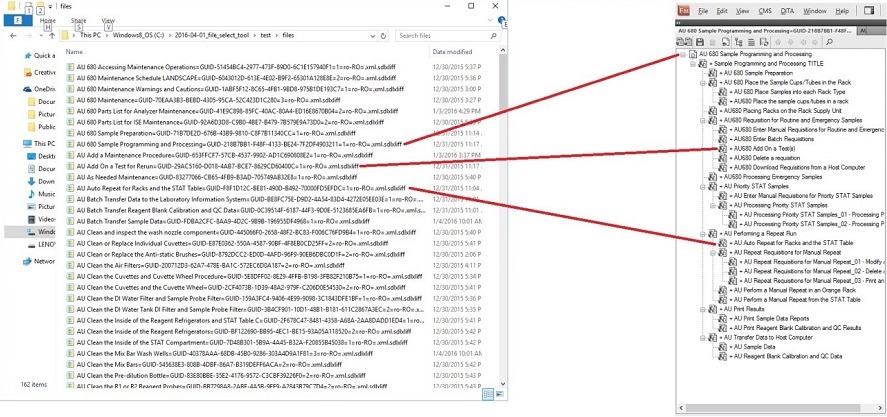
Once a document starts to use multiple elements and references, however, the chain of elements can become harder to understand. For that reason, Argos has created a plugin that uses the xslt transformation file supplied by a client in order to generate an XML preview of the DITA text directly in Trados Studio. You can see how this preview appears in the red box in the screenshot below. This way, even more complex layouts such as the ones shown below can be easily visualized by the linguist making translation a much simpler task.
If your business is planning to move its authoring to a DITA environment, talk to the Argos team about how we can help optimize your localization process with solutions for DITA.
Share this post
What to read next...
Want to know more?
The latest industry news, interviews, technologies, and resources.
View all resourcesGet in touch
We are committed to giving you freedom of choice while providing subject matter expertise and customized strategies to fit your business needs.
Contact us
